

La nova IA aconsegueix predir quan i per què té lloc l’agregació de proteïnes, un mecanisme vinculat a l’alzheimer i altres 50 malalties que afecten 500 milions de persones. Els resultats mostren un gran potencial per a la recerca en malalties neurodegeneratives i la millora de la producció de fàrmacs, reduint costos i augmentant l’eficiència. L’estudi, publicat a Science Advances, és fruit de la col·laboració entre el Centre de Regulació Genòmica (CRG) i l’Institut de Bioenginyeria de Catalunya (IBEC).

Una eina d’intel·ligència artificial ha permès fer un important pas en la traducció del llenguatge que utilitzen les proteïnes per dictar si formen agregats enganxosos, la presència dels quals es relaciona amb l’alzheimer i altres cinquanta tipus de malalties humanes. A diferència dels típics models d’IA de “caixa negra”, la nova eina, CANYA, es va dissenyar per poder explicar les seves decisions, revelant els patrons químics específics que impulsen o prevenen l’agregació nociva de les proteïnes.
El descobriment, publicat a la revista Science Advances, ha estat possible gràcies al conjunt més gran de dades sobre agregació de proteïnes creat fins ara. L’estudi ofereix nous coneixements sobre els mecanismes moleculars que causen l’agregació, que està relacionada amb malalties que afecten 500 milions de persones a tot el món.
L’aglomeració de proteïnes, o agregació amiloide, és un perill per a la salut que altera la funció normal de les cèl·lules. Quan certes parts de les proteïnes s’adhereixen entre si, aquestes es converteixen en masses denses i fibroses que tenen conseqüències patològiques.
L’agregació de proteïnes és un gran mal de cap per a les companyies farmacèutiques. CANYA pot ajudar a guiar els esforços per dissenyar anticossos i enzims que tinguin menys probabilitats d’adherir-se i reduir els contratemps en el procés.
Benedetta Bolognesi
Si bé l’estudi té algunes implicacions per accelerar els esforços en la recerca de malalties neurodegeneratives, el seu impacte més immediat serà en la biotecnologia. Molts fàrmacs són proteïnes i, sovint, la seva funció es veu obstaculitzada per agregacions no desitjades.
“L’agregació de proteïnes és un gran mal de cap per a les companyies farmacèutiques”, afirma la Dra. Benedetta Bolognesi, coautora principal de l’estudi i líder de grup a l’Institut de Bioenginyeria de Catalunya (IBEC).
“Si una proteïna terapèutica comença a agregar-se, els lots de fabricació poden fallar, cosa que costa temps i diners. CANYA pot ajudar a guiar els esforços per dissenyar anticossos i enzims que tinguin menys probabilitats d’adherir-se i reduir els contratemps en el procés”, afegeix.
Les agregacions proteiques es formen utilitzant un llenguatge encara poc conegut. Les proteïnes estan formades per vint tipus diferents d’aminoàcids. En lloc de les habituals lletres A, C, G, T que componen el llenguatge de l’ADN, el llenguatge d’una proteïna té vint lletres diferents, les combinacions de les quals formen “paraules” o “motius”.
S’ha intentat durant molt de temps desxifrar quines combinacions de motius causen l’agregació amiloide i quines altres permeten que les proteïnes es pleguin sense errors. Les eines d’intel·ligència artificial que tracten els aminoàcids com l’alfabet d’un idioma misteriós podrien ajudar a identificar les paraules o motius específics responsables, però la qualitat i el volum de les dades sobre l’agregació de proteïnes necessàries per alimentar els models han estat històricament escassos o s’han restringit a fragments de proteïnes molt petits.
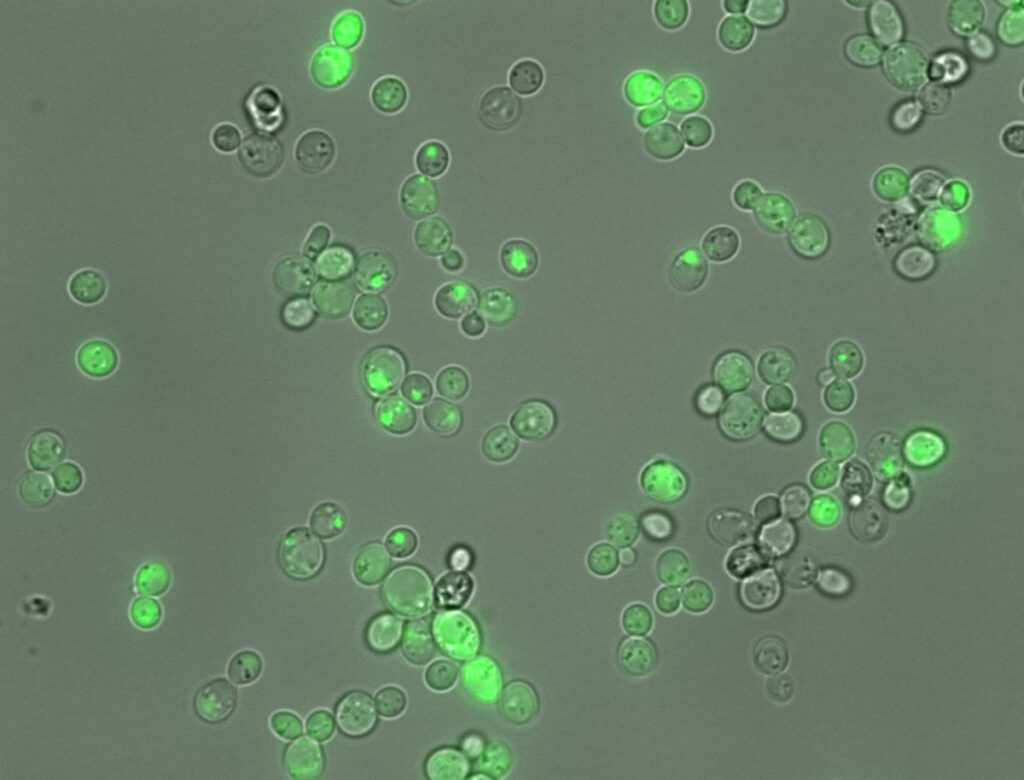
L’estudi ha abordat aquest repte mitjançant la realització d’experiments a gran escala. Els autors del treball van crear més de 100.000 fragments de proteïnes completament aleatoris des de zero, cadascun de 20 aminoàcids de llarg. La capacitat de cada fragment sintètic per agregar-se es va provar en cèl·lules de llevat vives. Així, si un fragment en concret desencadenés la formació d’agregats, les cèl·lules de llevat creixerien d’una manera particular que pot ser mesurada per determinar la causa i l’efecte.
Hem creat fragments de proteïnes aleatoris, incloses moltes versions que no es troben a la natura, proporcionant una gran quantitat de punts de dades per ajudar a comprendre les lleis més generals del comportament d’agregació
Mike Thompson
Al voltant d’un de cada cinc fragments de proteïna (21.936/100.000) va causar aglomeració, mentre que la resta no ho va fer. Si bé estudis anteriors han pogut rastrejar un grapat de seqüències, el nou conjunt de dades ha registrat un catàleg molt més gran de les diferents variants de proteïnes que poden causar l’agregació amiloide.
“Hem creat fragments de proteïnes aleatoris, incloses moltes versions que no es troben a la natura. L’evolució ha explorat només una fracció de totes les seqüències de proteïna possibles, mentre que el nostre enfocament ens ajuda a endinsar-nos a una galàxia molt més gran de possibilitats, proporcionant una gran quantitat de punts de dades per ajudar a comprendre les lleis més generals del comportament d’agregació”, explica el Dr. Mike Thompson, primer autor de l’estudi i investigador postdoctoral al Centre de Regulació Genòmica (CRG).
La gran quantitat de dades generades a partir dels experiments es va utilitzar per entrenar CANYA. L’equip va decidir crear-la fent servir els principis de la “IA explicable”, fent que els seus processos de presa de decisions fossin transparents i comprensibles per als humans. Això va significar sacrificar part del seu poder predictiu, que sol ser més gran a les IA de “caixa negra”. Malgrat això, CANYA va demostrar ser al voltant d’un 15% més precisa que els models existents.
En concret, CANYA és un model de convolució-atenció, una eina híbrida que manlleva de dues àrees diferents de la IA. Els models de convolució, com els que s’utilitzen en el reconeixement d’imatges, escanegen les fotos tot cercant característiques com una orella o un nas per identificar una cara. De manera equivalent, CANYA escaneja la cadena de proteïnes per trobar característiques significatives com motius o “paraules”.
D’altra banda, les eines de traducció d’idiomes utilitzen els models d’IA per identificar frases clau en una oració abans de decidir quina és la millor traducció. L’equip va incorporar aquesta tècnica per ajudar CANYA a descobrir quins motius són els més importants a escala general de tota la proteïna.
Junts, aquests dos enfocaments ajuden CANYA a veure de prop els motius locals i, alhora, a detectar la seva importància a gran escala. Es pot fer servir aquesta informació no només per predir quins motius a la cadena de proteïnes fomenten l’aglomeració, la bloquegen o provoquen un estadi intermedi, sinó també per comprendre per què.
Per exemple, CANYA va demostrar que les petites regions d’aminoàcids repel·lents a l’aigua són més propenses a provocar aglomeració, mentre que alguns motius tenen un major impacte en l’aglomeració si es troben cap a l’inici d’una seqüència de proteïnes en lloc de cap al final. Aquestes observacions s’alineen amb troballes prèvies que s’han vist sota el microscopi en fibril·les amiloides conegudes.
Però CANYA també va trobar noves regles que dirigeixen l’agregació de proteïnes. Per exemple, es pensava que certs components bàsics de les proteïnes, els anomenats aminoàcids carregats, eviten l’aglomeració. Però resulta que, en el context d’altres blocs de construcció específics, en realitat poden promoure l’aglomeració.
En la seva forma actual, CANYA explica principalment l’agregació de proteïnes en termes de sí o no, és a dir, funciona com un anomenat “classificador”. Com a treball futur, l’equip vol refinar el sistema perquè pugui predir i comparar les velocitats d’agregació en lloc de només la probabilitat d’agregació. Això podria ajudar a predir quines variants de proteïnes formen agregats ràpidament i quines ho fan més lentament, un factor vital en les malalties neurodegeneratives en què el moment de la formació d’amiloide és tan important com el fet mateix que passi.
Aquest projecte és un gran exemple de com la combinació de la generació de dades a gran escala amb la IA pot accelerar la recerca. També es tracta d’un mètode molt rendible per generar dades.
Ben Lehner
“Hi ha 1.024 quintilions de formes de crear un fragment de proteïna de 20 aminoàcids de llarg. Fins ara, hem entrenat una IA amb només 100.000 fragments. Volem millorar el procés creant més fragments i més grans. Tot i que aquest és només el primer pas, el nostre treball mostra que és possible desxifrar el llenguatge de l’agregació de proteïnes. Això és increïblement important per a la nostra comprensió de les malalties humanes, però també per guiar els esforços de la biologia sintètica”, conclou la Dra. Bolognesi.
“Aquest projecte és un gran exemple de com la combinació de la generació de dades a gran escala amb la IA pot accelerar la recerca. També es tracta d’un mètode molt rendible per generar dades”, diu el professor de recerca ICREA Ben Lehner, coautor principal de l’estudi i cap de grup al Centre de Regulació Genòmica (CRG) i l’Institut Wellcome Sanger.
“Usant la síntesi i seqüenciació d’ADN, podem realitzar centenars de milers d’experiments en un sol tub, generant les dades que necessitem per entrenar models d’IA. Aquest és un enfocament que estem aplicant a molts problemes difícils de la biologia, amb l’objectiu que aquesta sigui predictible i programable”, afegeix Dr. Lehner.
L’estudi és fruit de la col·laboració entre el laboratori del professor de recerca ICREA Ben Lehner al Centre de Regulació Genòmica (CRG) i el laboratori de Benedetta Bolognesi a l’Institut de Bioenginyeria de Catalunya (IBEC). Equips del Laboratori Cold Spring Harbor (CSHL) i l’Institut Wellcome Sanger també van col·laborar en l’estudi. El treball ha rebut finançament de la Fundació de Recerca “la Caixa”, el Consell Europeu de Recerca i el Ministeri de Ciència i Innovació.
Reference article
Mike Thompson, Mariano Martín, Trinidad Sanmartín Olmo, Chandana Rajesh, Peter K. Koo, Benedetta Bolognesi, Ben Lehner. Massive experimental quantification allows interpretable deep learning of protein aggregation. Science Advances (2025). DOI: 10.1126/sciadv.adt5111



